Google Gemini 3 Flash Released: The Fastest AI Model in History?

 English
English Russian
Russian Español
Español Français
Français Deutsch
Deutsch हिन्दी
हिन्दी සිංහල
සිංහල 中文
中文 日本語
日本語

The AI speed war is officially over. Just days after OpenAI released GPT-5.2, Google has responded with a massive counter-attack. On December 17, 2025, Google officially launched Gemini 3 Flash.
This is not just a minor update. While Gemini 3 Pro is designed for deep thinking, "Flash" is designed for instantaneous responses. Google claims it is the first "Frontier Model" to achieve sub-100 millisecond latency, making it feel faster than human thought.
In this article, we break down the insane new specs, the aggressive pricing, and how it integrates with Google's new "Antigravity" coding platform.
What is Gemini 3 Flash?
Gemini 3 Flash is a "distilled" version of the massive Gemini 3 model. It is designed to be lightweight, incredibly cheap, and fast enough to power real-time voice agents and robotics.
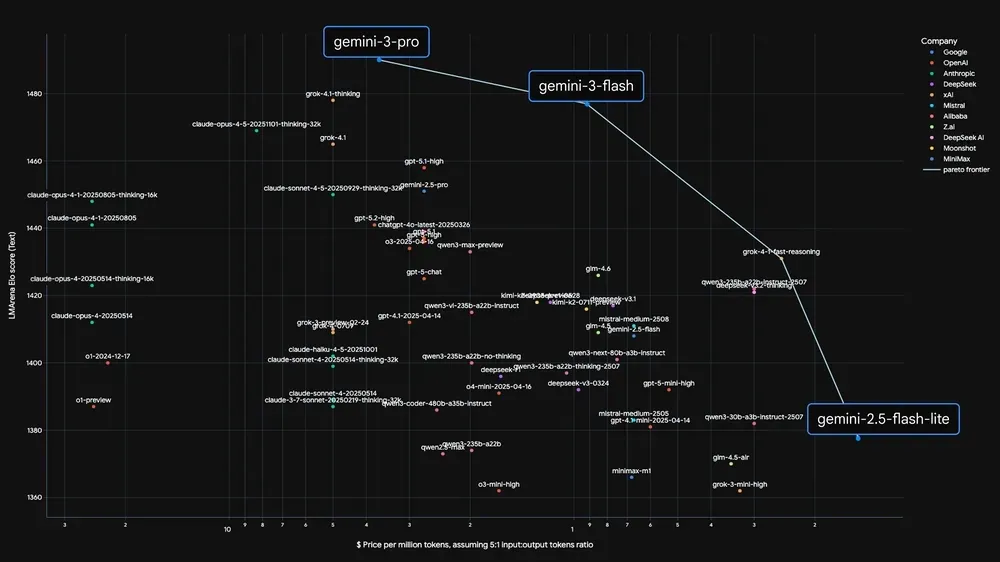
According to Google CEO Sundar Pichai, this model pushes the "Pareto Frontier," meaning it delivers the intelligence of a Pro model (beating the older Gemini 2.5 Pro) at a fraction of the cost and size.
Top 3 Killer Features
1. "Blink of an Eye" Speed
The standout feature is latency. Gemini 3 Flash is approximately 3x faster than its predecessor.
- Real-World Impact: If you use it for a voice assistant or a customer service bot, there is zero pause between you speaking and the AI answering. It feels like a real phone conversation.
- Tech Spec: It supports "Context Caching" by default, meaning if you send it the same document twice, it remembers it instantly and answers even faster the second time.
2. Smarter Than the Old "Pro"
Usually, the "Flash" or "Mini" models are dumbed down. Not this time.
- Benchmarks: Gemini 3 Flash scored 90.4% on the GPQA Diamond benchmark (PhD-level science), which is higher than GPT-4o and Gemini 2.5 Pro.
- Coding: It is now the default model inside Google Antigravity (Google's new agentic IDE), capable of editing hundreds of lines of code in seconds.
3. Aggressive Pricing
Google is trying to undercut OpenAI.
- Input Cost: $0.50 per 1 million tokens.
- Output Cost: $3.00 per 1 million tokens.
- This makes it roughly 50% cheaper than OpenAI's GPT-5.2 Instant model, making it the obvious choice for developers building heavy applications.
Gemini 3 Flash vs. GPT-5.2 Instant
The two tech giants are now neck-and-neck.
| Feature | Gemini 3 Flash | GPT-5.2 Instant |
|---|---|---|
| Speed | <100ms (Winner) | ~250ms |
| Context Window | 2 Million Tokens | 128k Tokens |
| Multimodal | Native Video/Audio | Audio Only |
| Pricing | $0.50 / 1M | $1.00 / 1M |
| Ecosystem | Google Workspace / Android | Microsoft 365 |
Verdict: If you need to process massive videos or long documents, Gemini 3 Flash wins easily due to its 2-million-token window. However, for pure text generation, both are incredibly capable.
How to Use It Today
You don't need to wait. Google has rolled this out globally immediately:
- Google AI Studio: Developers can access the API right now.
- Gemini App: If you are a free user, your default model has effectively been upgraded to Gemini 3 Flash starting today.
- Android: The "Gemini Nano" on Pixel phones is being updated to use the Flash architecture for on-device processing.
Conclusion
Google has proven that "Fast" doesn't have to mean "Stupid." With Gemini 3 Flash, we finally have an AI that is smart enough to write code but fast enough to talk to in real-time.
For developers and businesses, the 2026 AI roadmap just got a lot cheaper and a lot faster.
Source - blog.google , deepmind.google , vercel.com
Frequently Asked Questions